Power Automate
Why Extract Pages from PDFs Using Power Automate?
The Need for Extracting Specific Pages from Large PDFs
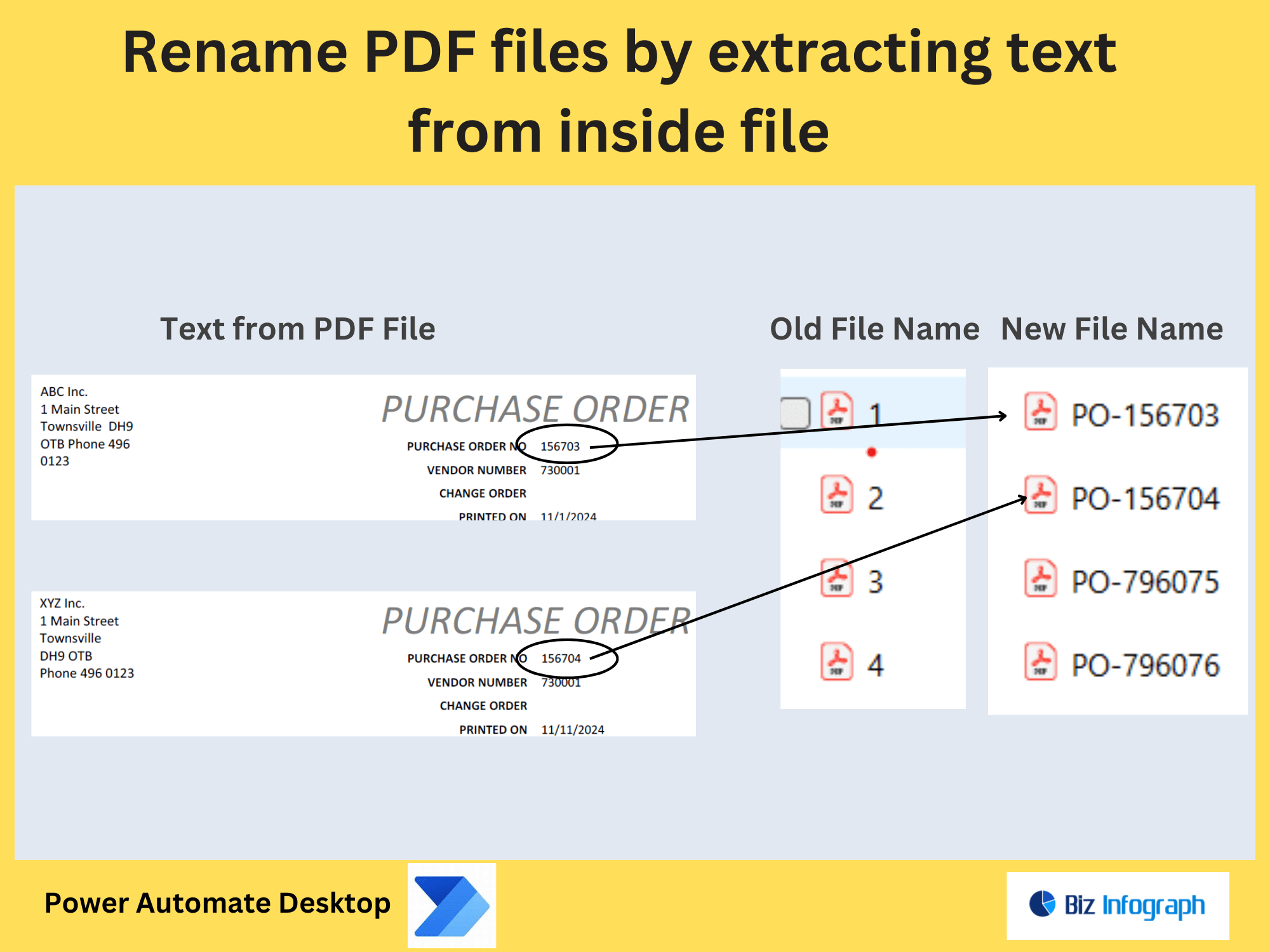
Extracting specific pages from a PDF is essential when dealing with large documents like reports, contracts, or invoices. Manual extraction is error-prone, especially with page ranges spanning hundreds of pages. For example, extracting a single page containing a client’s signature or a PDF table from a lengthy report. This is critical for workflows requiring structured data or compliance checks.
Benefits of Automating PDF Page Extraction
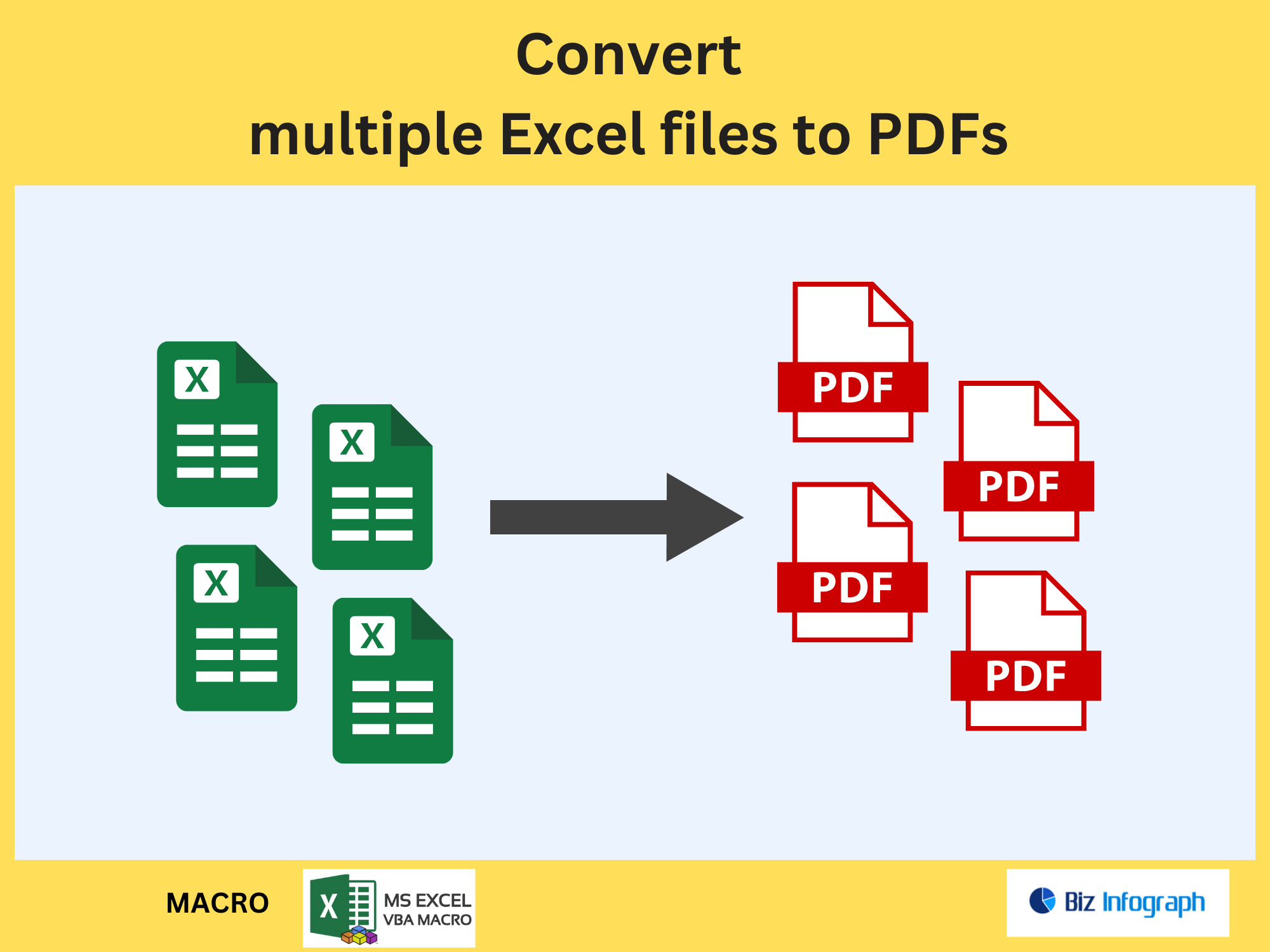
Automating page extraction with Power Automate saves time and reduces errors. Use the Extract Pages from PDF Action to isolate specific pages or page ranges and save them as a new PDF file. This is ideal for scenarios like splitting invoices from bulk PDF files or creating summaries from lengthy documents. By leveraging OCR for scanned PDFs or Adobe Tech Blog-recommended methods, users ensure text and tables remain intact. Automation also supports merging multiple PDFs into a single file, streamlining workflows for staff software engineers or compliance teams.
How to Extract Pages from PDFs with Power Automate
Setting Up Power Automate for PDF Page Extraction
Start by configuring a workflow in Power Automate Desktop or cloud flows. Use triggers like “Receive an Email” with attachments or SharePoint folder updates. Integrate Adobe PDF Extract API or third-party tools like PDF4Me Extract Pages from PDF Action to define page ranges or single pages. For example, extract pages 5–10 from a source PDF and save them as a new PDF file. Ensure the PDF structure is preserved, especially for text from a PDF or tables.
Step-by-Step Guide to Extract Pages from PDFs
Splitting PDFs by Page Range or Keywords
Trigger: Use a SharePoint folder trigger or email attachment.
Extract Pages: Use PDF4Me Extract Pages from PDF Action to define a page range (e.g., 1–5) or extract pages containing keywords like “Invoice.”
Save Output: Save extracted pages as a new PDF file using Create File Action.
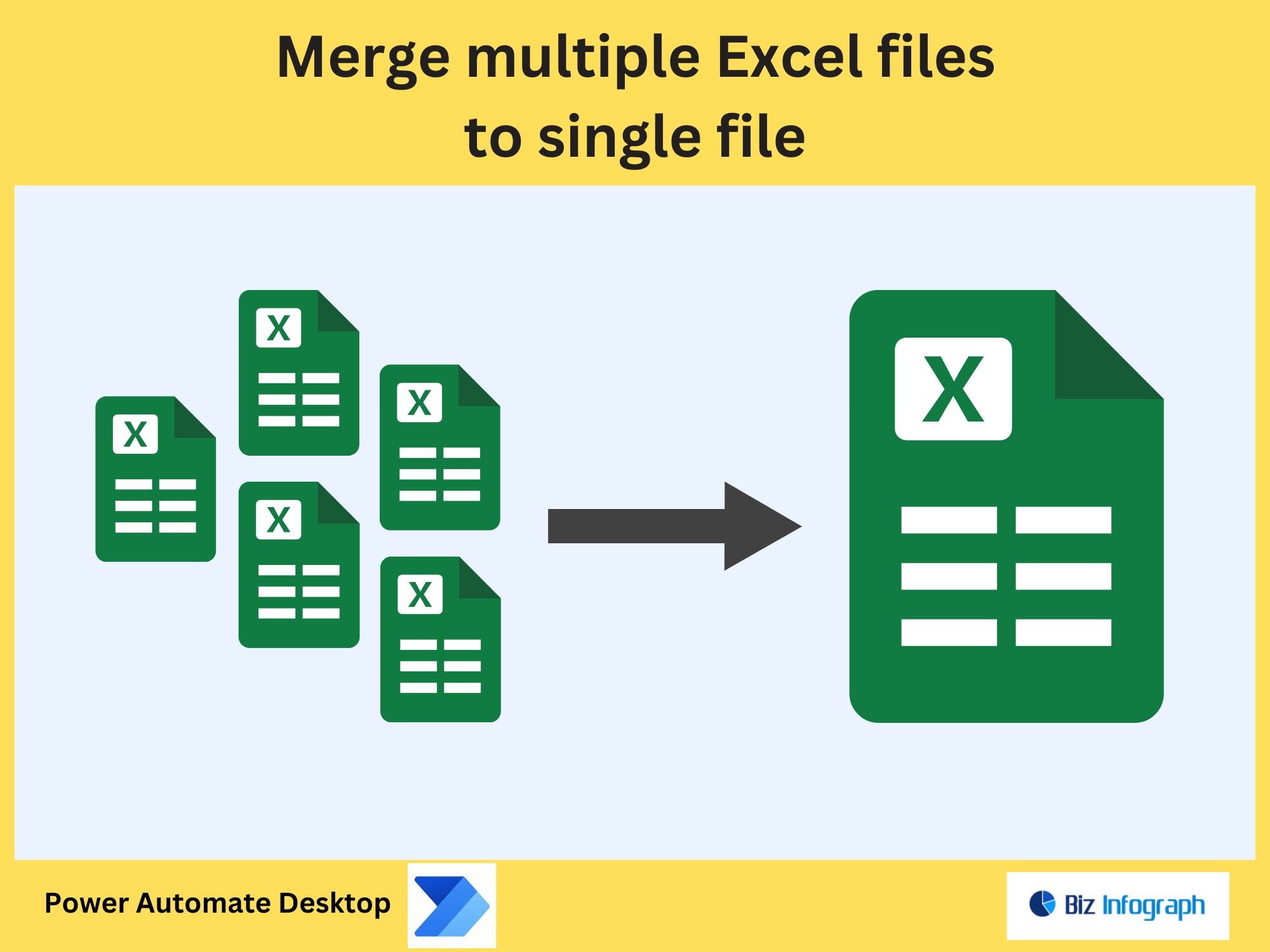
Merge: Optionally, merge PDF files into a single PDF for consolidated storage.
Handling Scanned PDFs with OCR
For image-based PDFs, integrate OCR actions to convert scans to text before extraction. Use Power Automate’s OCR tools to ensure extracted pages retain text from a PDF accurately.
Advanced Techniques for PDF Automation
Merging Extracted Pages into Structured Workflows
Combine extracted pages with JSON parsing or natural language processing to auto-tag content. For example, extract tables from a PDF document and feed them into a database.
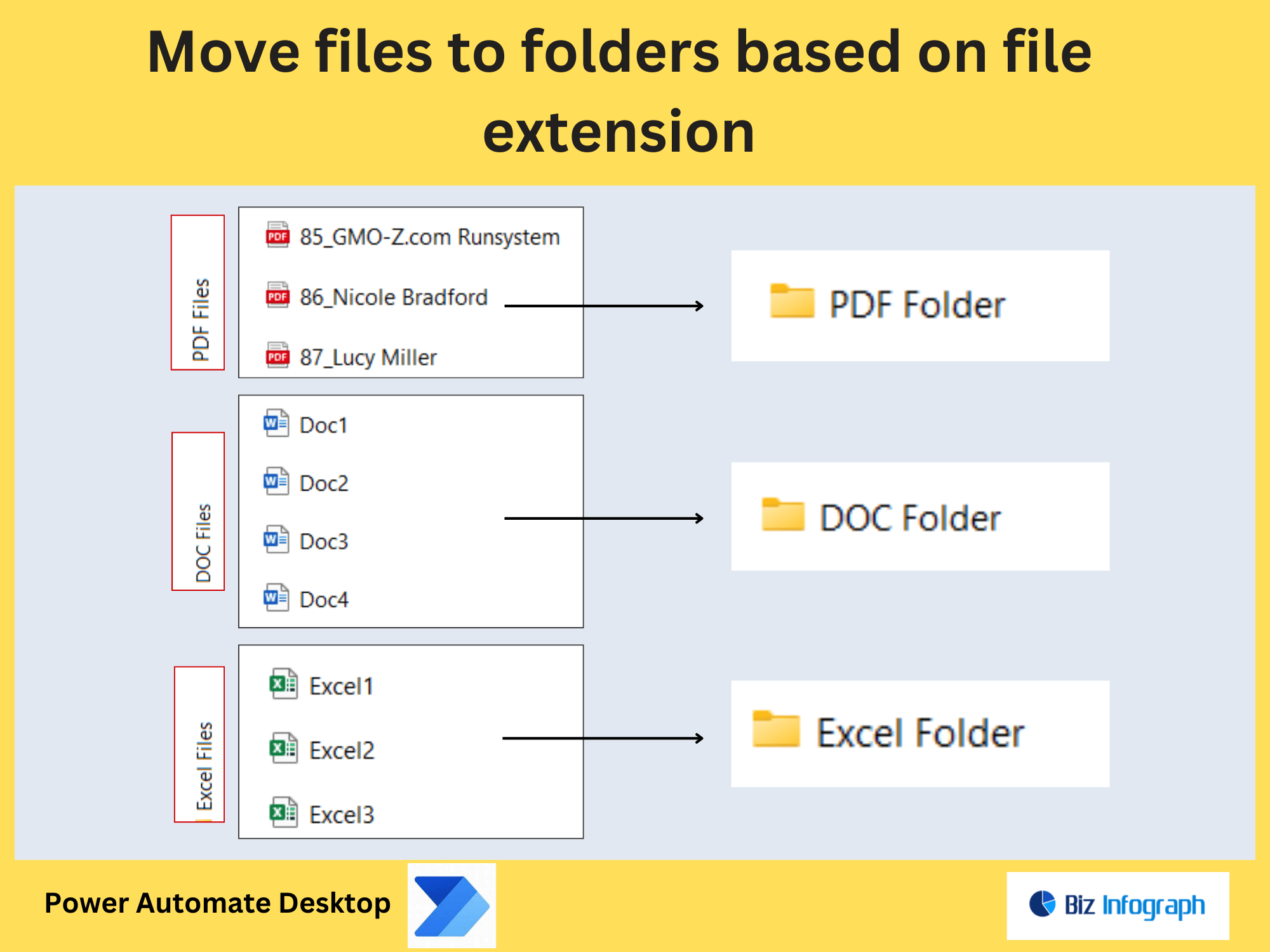
Bulk Processing with Power Automate Desktop
Use Power Automate Desktop to split PDFs based on page count (e.g., every 10 pages) across multiple files. Ideal for processing large volumes of documents in modern e-commerce storefronts.
Why Extract Specific Text from PDFs Using Power Automate?
The Need for Targeted Text Extraction
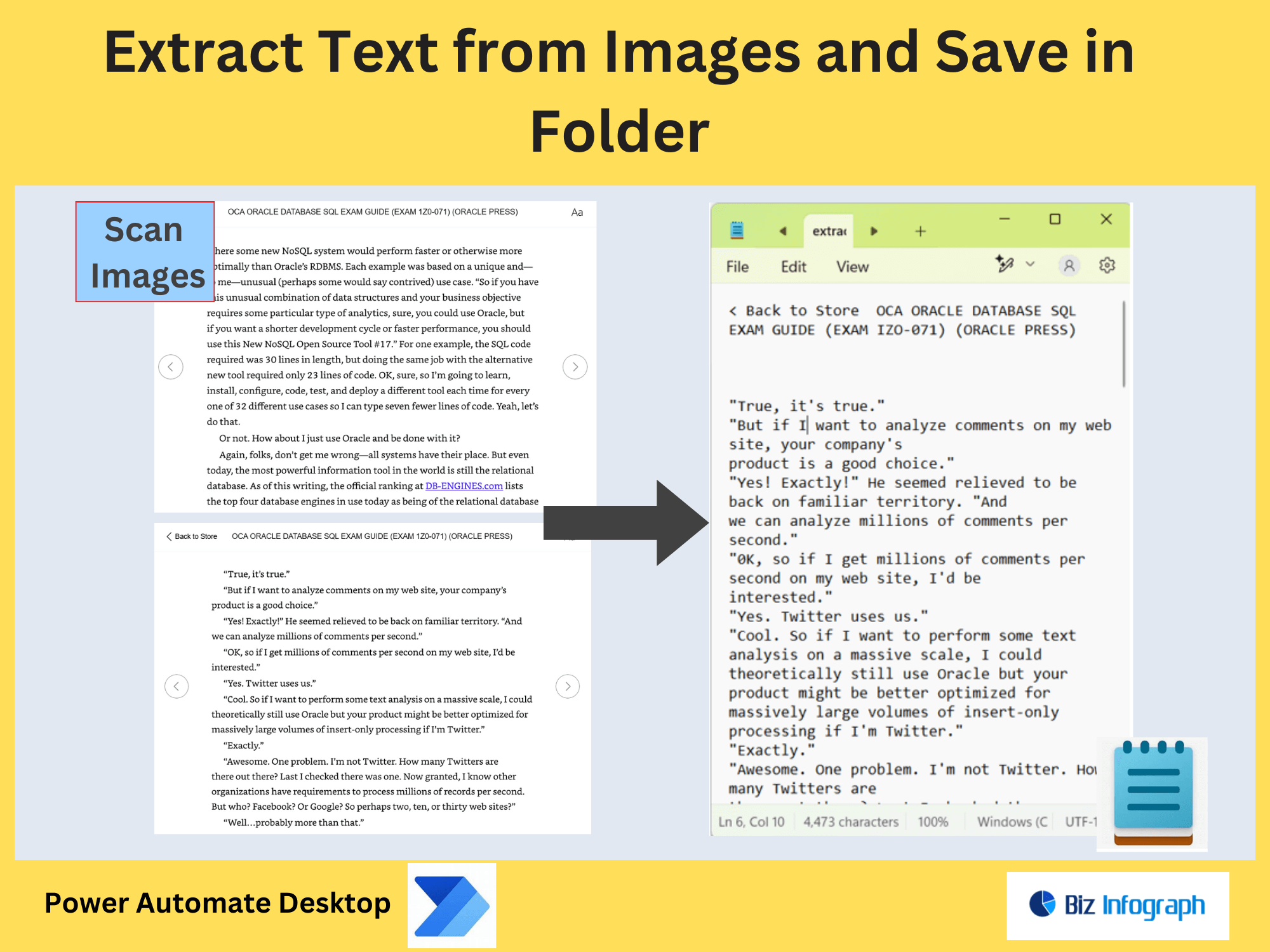
Extracting specific text from a PDF (e.g., dates, invoice numbers) is critical for workflows like compliance checks or data entry. Manual extraction from PDF files is inefficient, especially with scanned PDFs requiring OCR.
Benefits of Automating Text Retrieval
Microsoft Power Automate automates text extraction using Adobe PDF Extract API or OCR, ensuring accuracy. Parse structured data like PDF tables or converting date strings into standardized formats.
How to Extract Specific Text from PDFs
Configuring OCR and Text Parsing
To extract text from a PDF containing scanned or image-based content integrates with OCR tools like PDF Extract API or Azure Cognitive Services. Begin by configuring a workflow triggered by events such as receiving an email with attachments or a file upload to SharePoint. Use the Extract Pages from PDF Action to isolate specific pages from a source PDF, then apply OCR to convert scanned text into machine-readable format. For example, a staff software engineer might use OCR to parse technical diagrams or PDF tables from a lot of big documents, ensuring data like converting date strings is standardized.
Set the language field (defaults to English) to improve accuracy and use natural language processing to categorize extracted text (e.g., "Project Code" or "Client Name"). For scanned PDFs, leverage PDF4Me Extract Pages from PDF to handle complex layouts. If errors occur—such as low-resolution scans—add conditional checks to flag issues. A sample flow could involve splitting a single PDF into multiple PDFs based on page range, then using OCR to extract structured data like invoice numbers. This is critical for modern e-commerce storefronts needing to process bulk orders or contracts.
Exporting Data to Structured Formats
After extracting text, export it to structured formats like JSON, Excel, or databases using Power Automate. For instance:
-
Parse JSON: Map extracted PDF data (e.g., text from a PDF table) to fields like "Product ID" or "Price."
-
Create File Action: Generate Excel files from parsed data and save them to SharePoint or OneDrive.
-
Merge PDF Files: Combine file pages to new PDF documents for reporting.
A practical scenario: A logistics team uses Power Automate Desktop to split the PDFs containing shipping labels into single page files, extracts addresses via OCR, and appends the data to a CRM system. For compliance, automate converting date strings to a standard format (e.g., YYYY-MM-DD) using expressions. Advanced users can integrate Adobe Tech Blog-recommended methods to preserve PDF structure when exporting tables or diagrams.
To handle multiple PDFs, use Apply to Each Loop to process batches, then append results to a single file. For example, extract financial data from edge delivery services for commerce reports, convert it to JSON, and feed it into analytics tools. This eliminates manual data entry and ensures scalability for large documents.
Advanced Text Extraction Strategies
Integrating with NLP and AI Tools
Integrating natural language processing (NLP) and AI tools with Power Automate transforms raw text into actionable insights. For example, Azure Cognitive Services can categorize extracted text, identify entities (e.g., names, dates), or detect sentiment in customer feedback PDFs. A healthcare provider might use NLP to extract patient diagnoses from clinical reports and auto-tag them in a database. Similarly, AI tools can automate contract analysis by flagging non-standard clauses or summarizing terms. By embedding these tools into Power Automate workflows, businesses can process unstructured PDFs at scale, turning text into structured data for CRM, ERP, or BI systems.
Automating Multi-PDF Workflows
Automating multi-PDF workflows with Power Automate streamlines bulk operations like batch extraction, merging, or splitting. For example, use Apply to Each Loop to process hundreds of invoices stored in SharePoint, extract payment terms and amounts, and compile results into a single PDF or Excel report. For large-scale tasks, Power Automate Desktop can split PDFs by page count (e.g., every 10 pages) or keywords, then merge relevant sections into new files. Integrate error handling to manage exceptions, such as corrupted files or missing pages. A logistics company might automate extraction of delivery addresses from multiple PDFs and feed them into a route optimization tool, reducing manual data entry and improving operational efficiency.
For ready-to-use Dashboard Templates:
- Financial Dashboards
- Sales Dashboards
- HR Dashboards
- Data Visualization Charts
- Power BI – Biz Infograph
- Automation – Biz Infograph