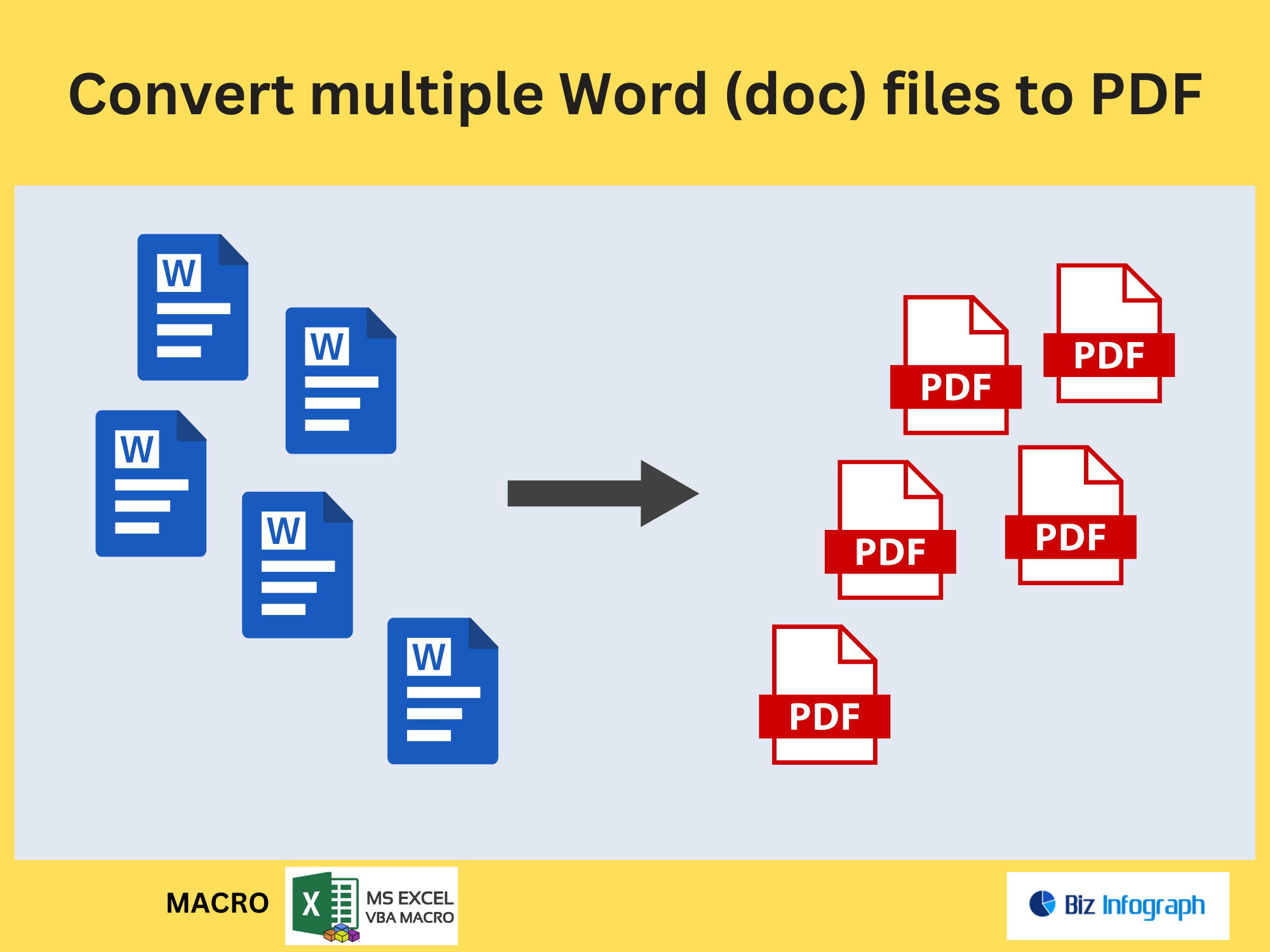
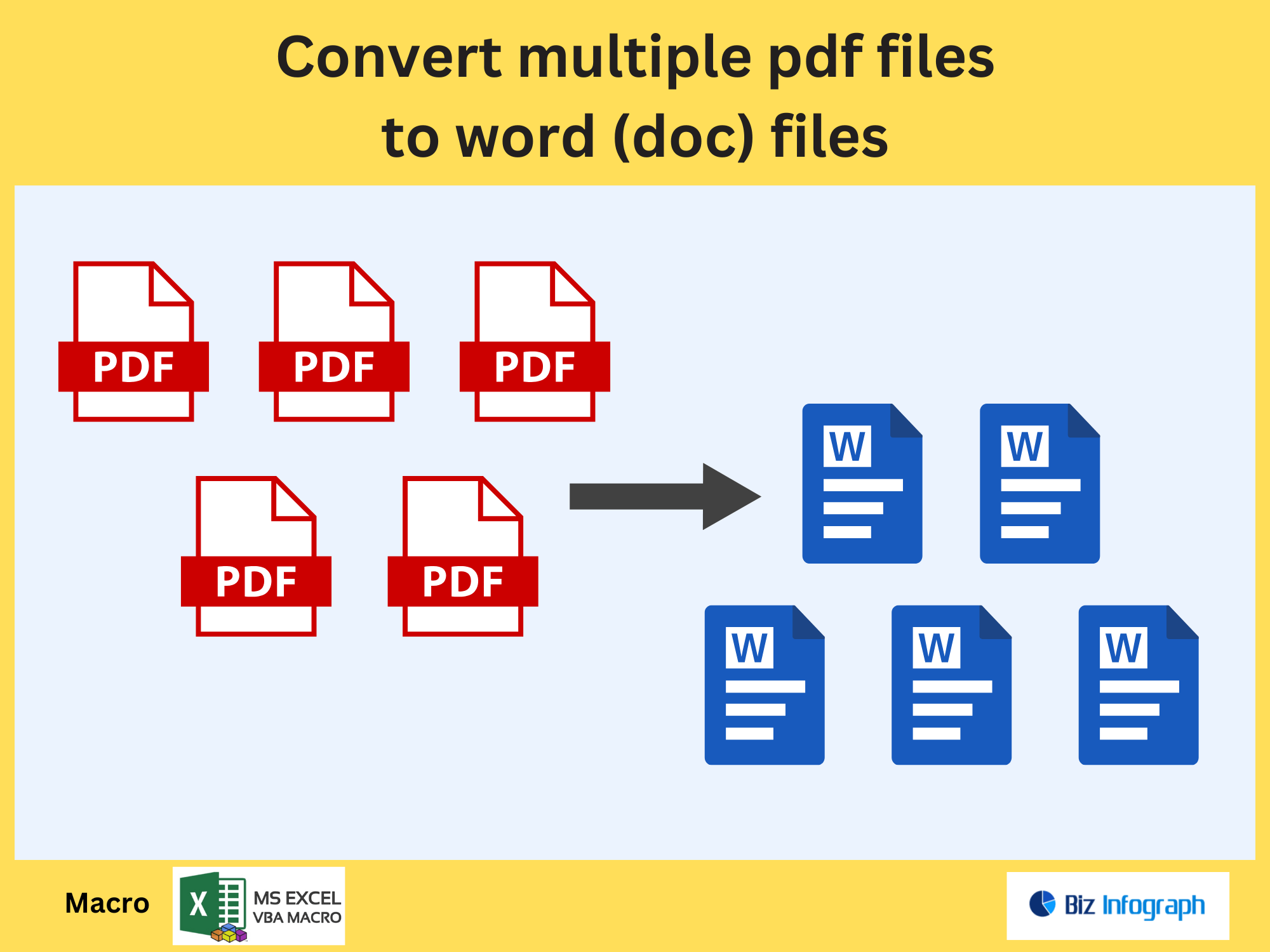
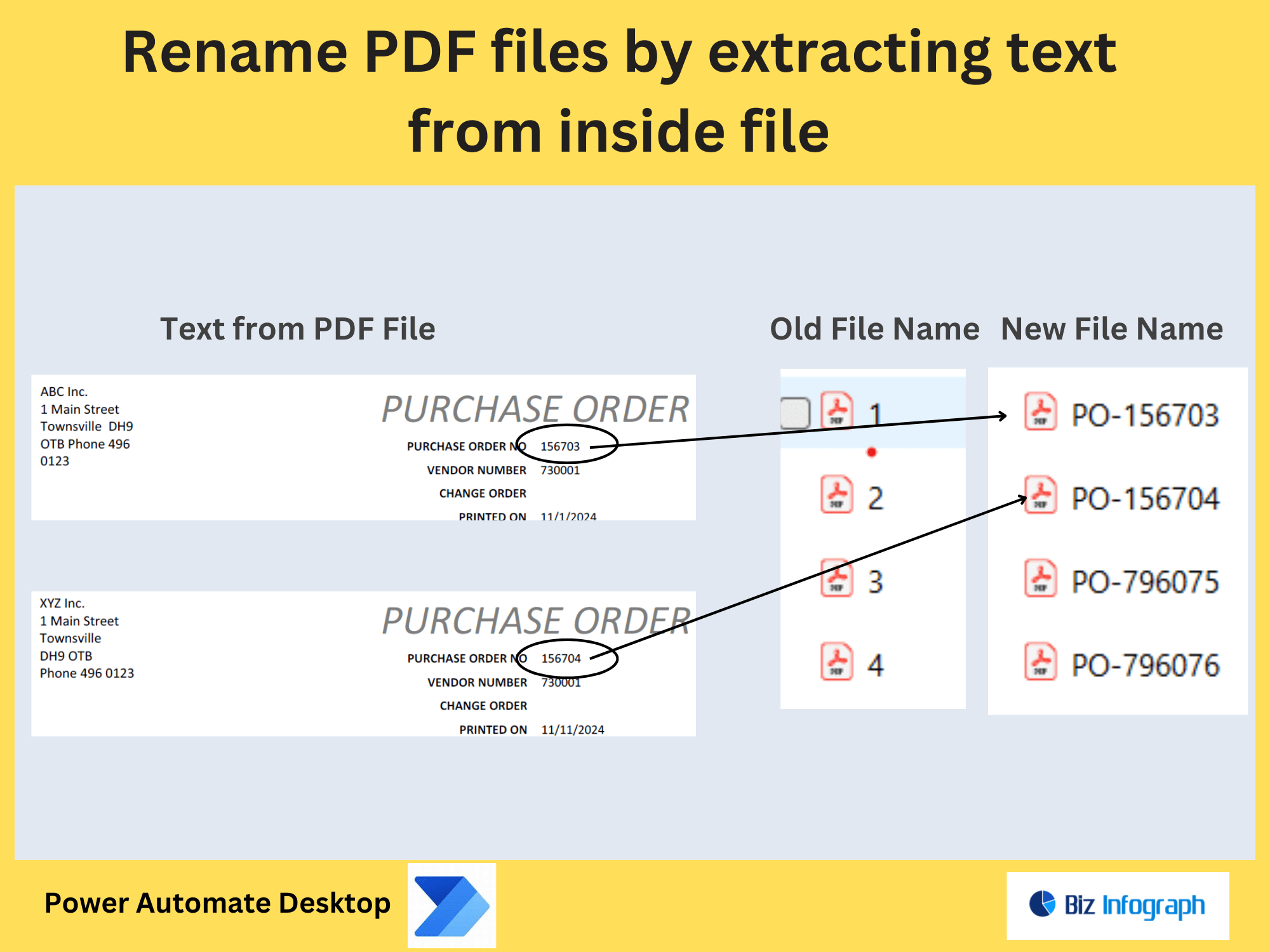
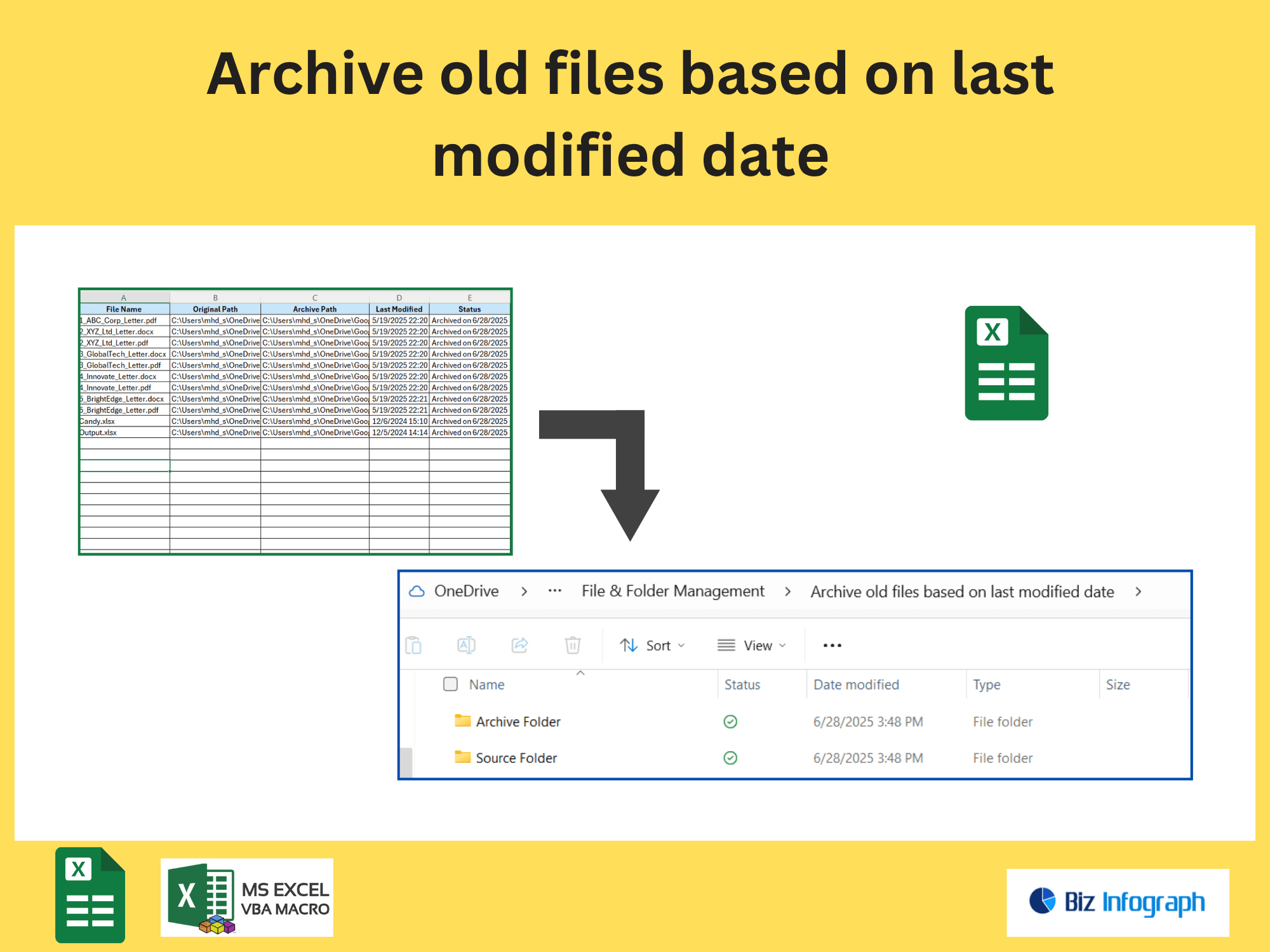
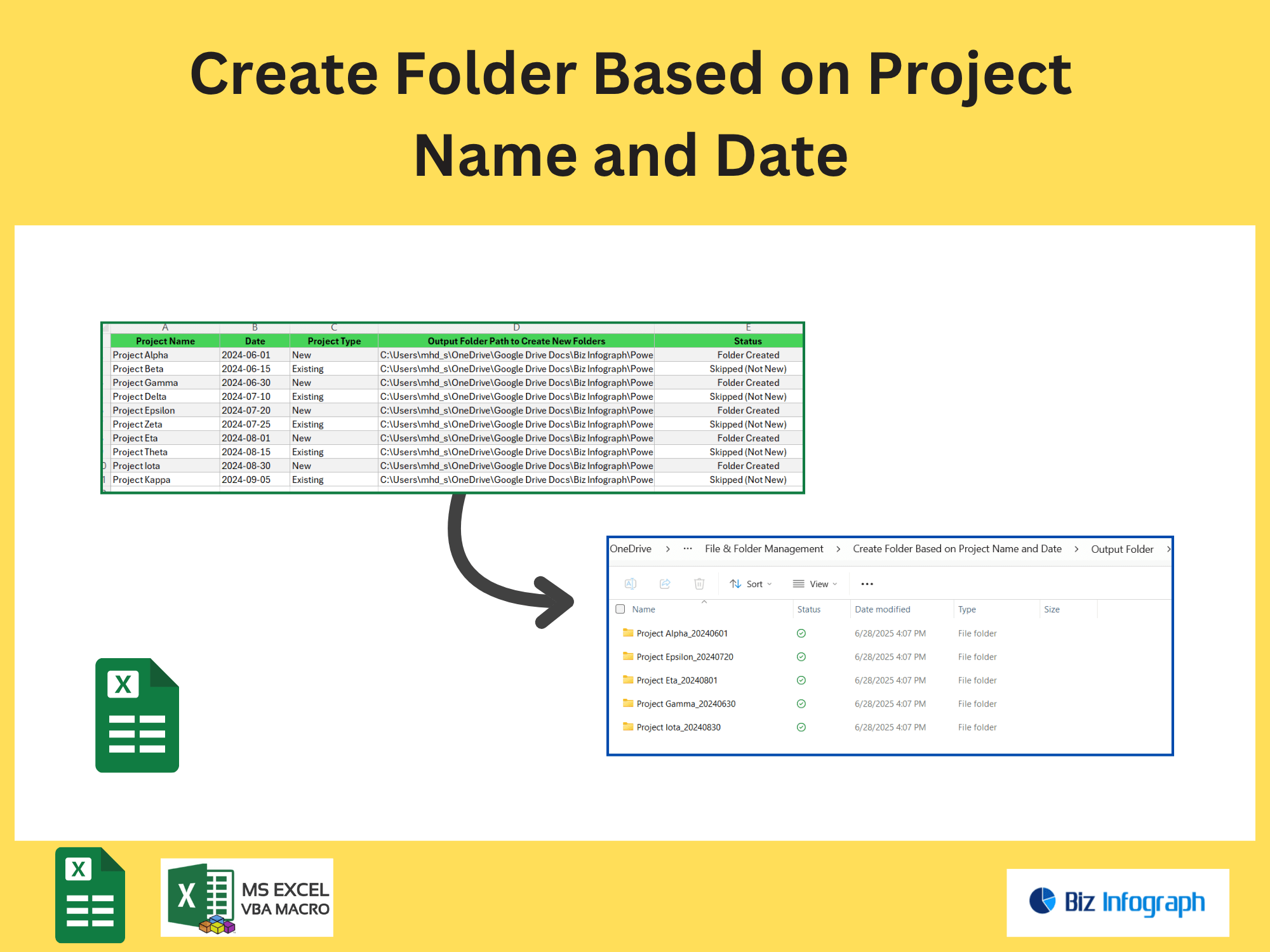
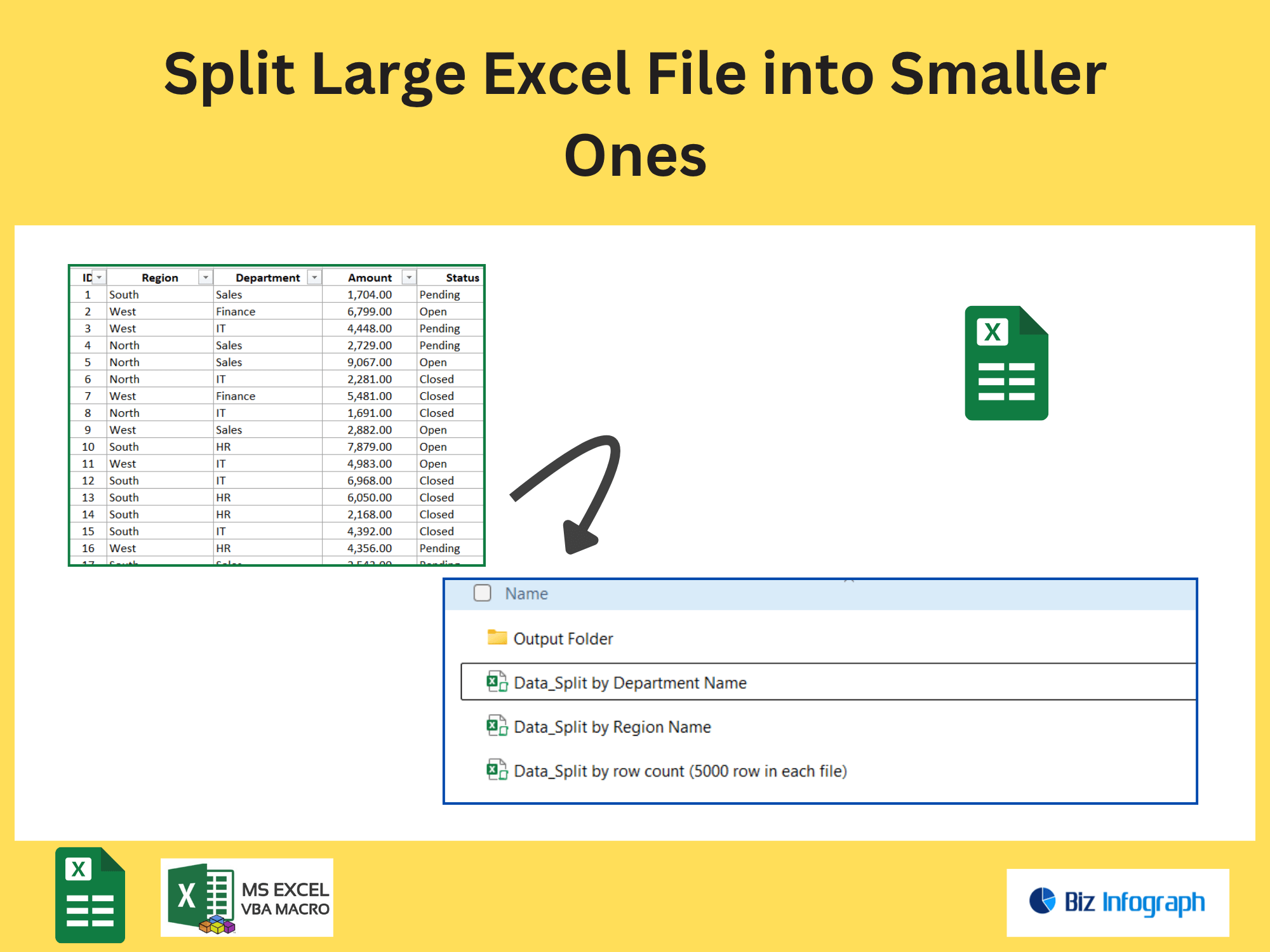
Extract Pages Containing Specific Text from a PDF file by Power Automate
Why Automate PDF Text Extraction with Power Automate?
The Need for Efficient PDF Content Extraction
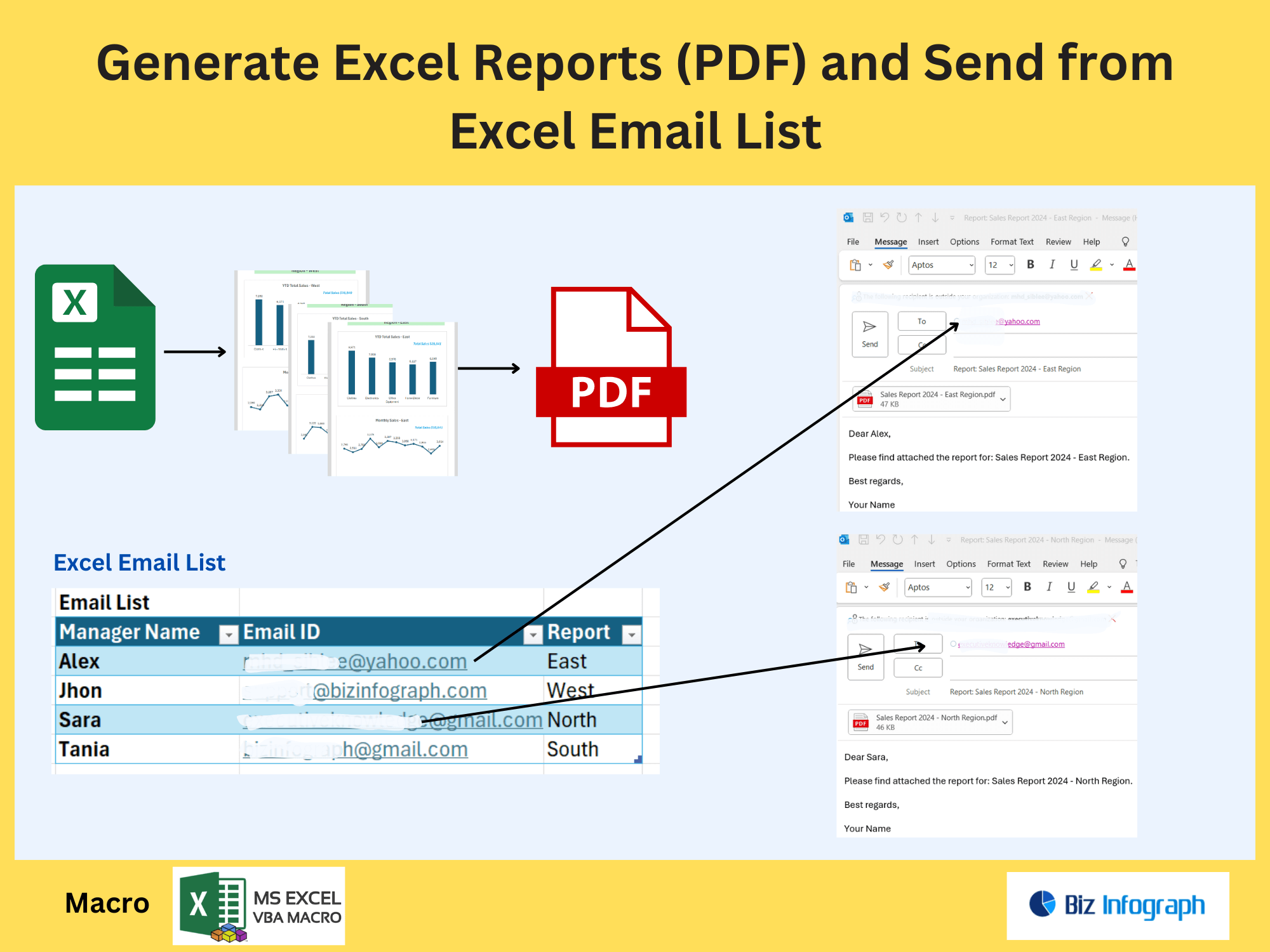
In modern workflows, manually searching for specific text in a PDF file is time-consuming and error-prone. Businesses often need to extract text from PDFs for tasks like data analysis, compliance checks, or report generation. Power Automate streamlines this process by automating text extraction, enabling users to extract pages, images, or specific content without manual intervention. For example, extracting invoice numbers or client details from PDF files becomes seamless with automation. This reduces human error and accelerates processes like document indexing or formatting extracted data for use in other systems.
Benefits of Automating Text Extraction from PDFs
Automating text extraction from PDFs using Power Automate improves accuracy and efficiency. It eliminates repetitive tasks, such as manually copying text or extracting images from hundreds of documents. Automation ensures consistent formatting of extracted content, whether saving it to a new PDF or integrating it into databases. For instance, legal teams can extract specific clauses from contracts, while HR departments can pull candidate details from resumes. By leveraging Power Automate, organizations reduce processing time and focus on higher-value tasks, enhancing productivity.
How to Extract Specific Text from PDF Files Using Power Automate
Setting Up Power Automate for PDF Text Extraction
To begin, configure Power Automate to handle PDF files by integrating with tools like Adobe PDF Services or third-party connectors. Use triggers such as “When a file is added to a folder” to initiate workflows. Actions like extract text from PDF or extract pages can be added to parse content. For example, set up a flow to scan uploaded PDF files in SharePoint, extract keywords, and store results in Excel. Ensure proper formatting rules are applied to organize extracted data.
Using OCR to Extract Text from PDFs document
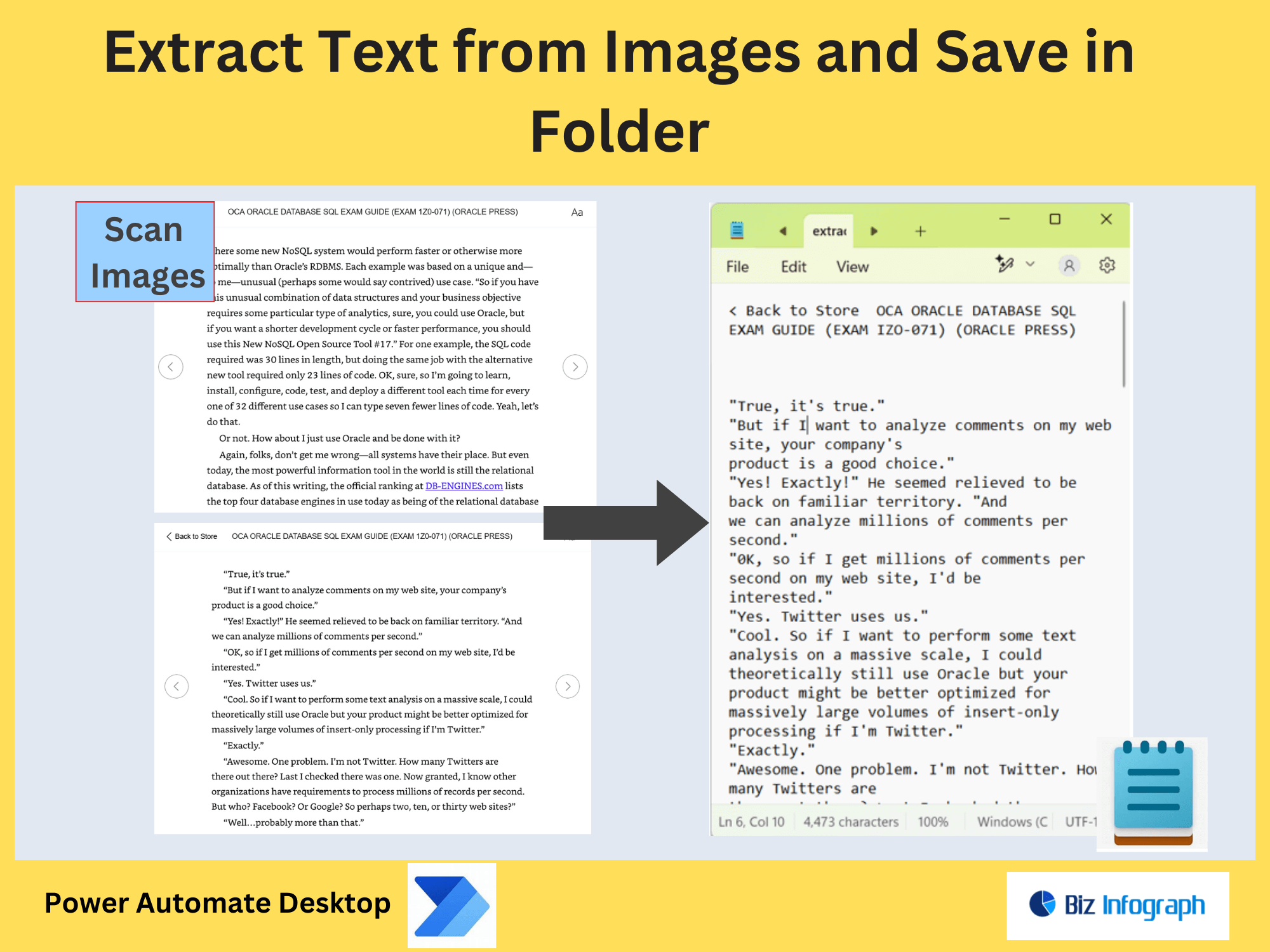
For scanned PDFs or image-based files, use Optical Character Recognition (OCR) in Power Automate to extract text accurately. Tools like Azure Cognitive Services or Adobe’s OCR engine can convert images within PDF files into machine-readable text. Configure the workflow to process bulk PDFs, apply OCR, and save the text to a database or new PDF. This is ideal for digitizing legacy documents or processing invoices where specific text (e.g., dates, amounts) must be isolated.
Step-by-Step Guide to Extract and Format Text from PDFs
Extracting Text from PDF Files
Use Power Automate actions like “Extract Text from PDF” to pull content based on predefined criteria. For example, extract all text containing a keyword like “Invoice ID” or regex patterns. Store results in variables for further processing. If dealing with PDF files with mixed content, combine text extraction with extract images or extract pages to isolate relevant sections.
Formatting and Organizing Extracted Text
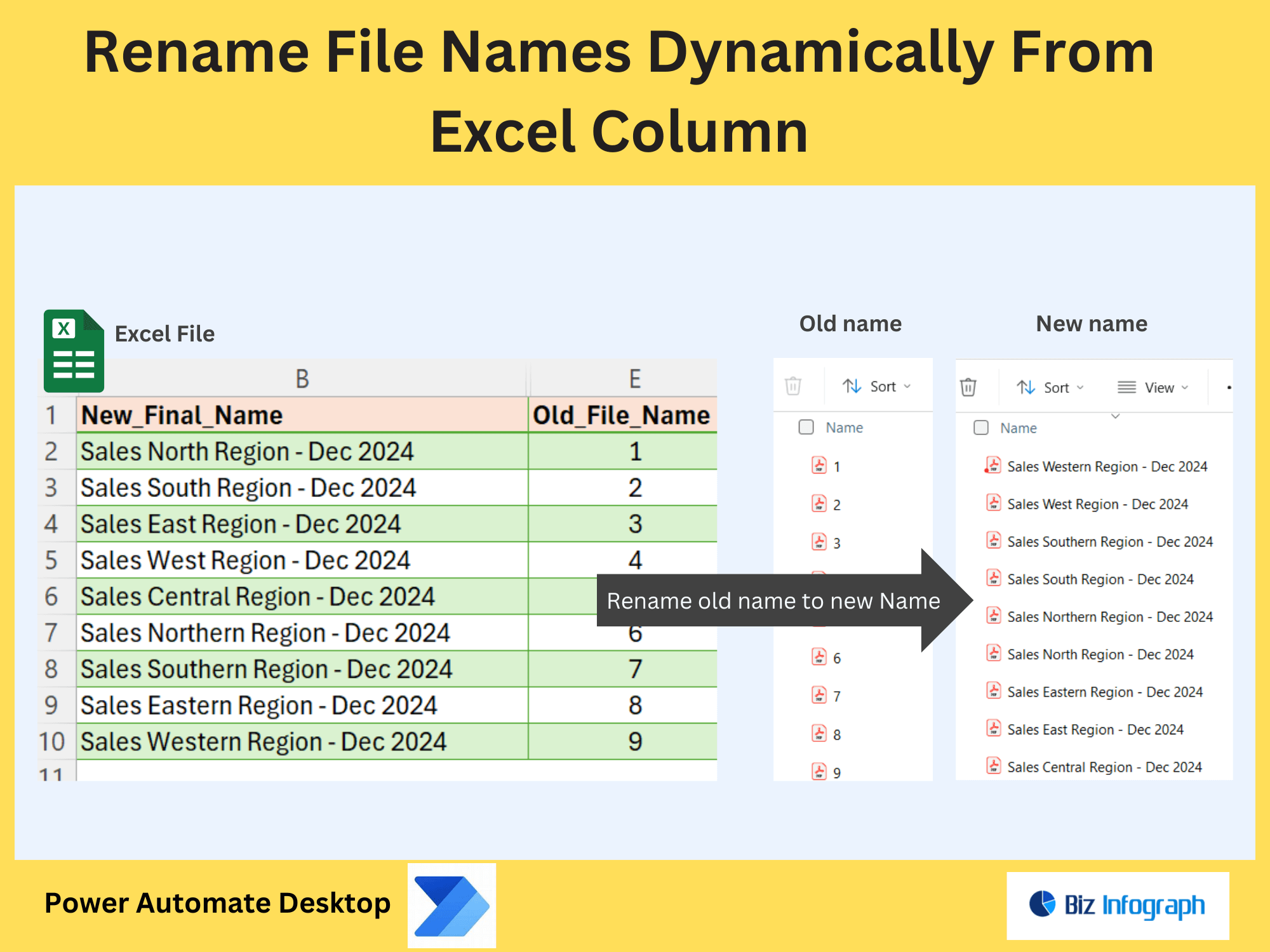
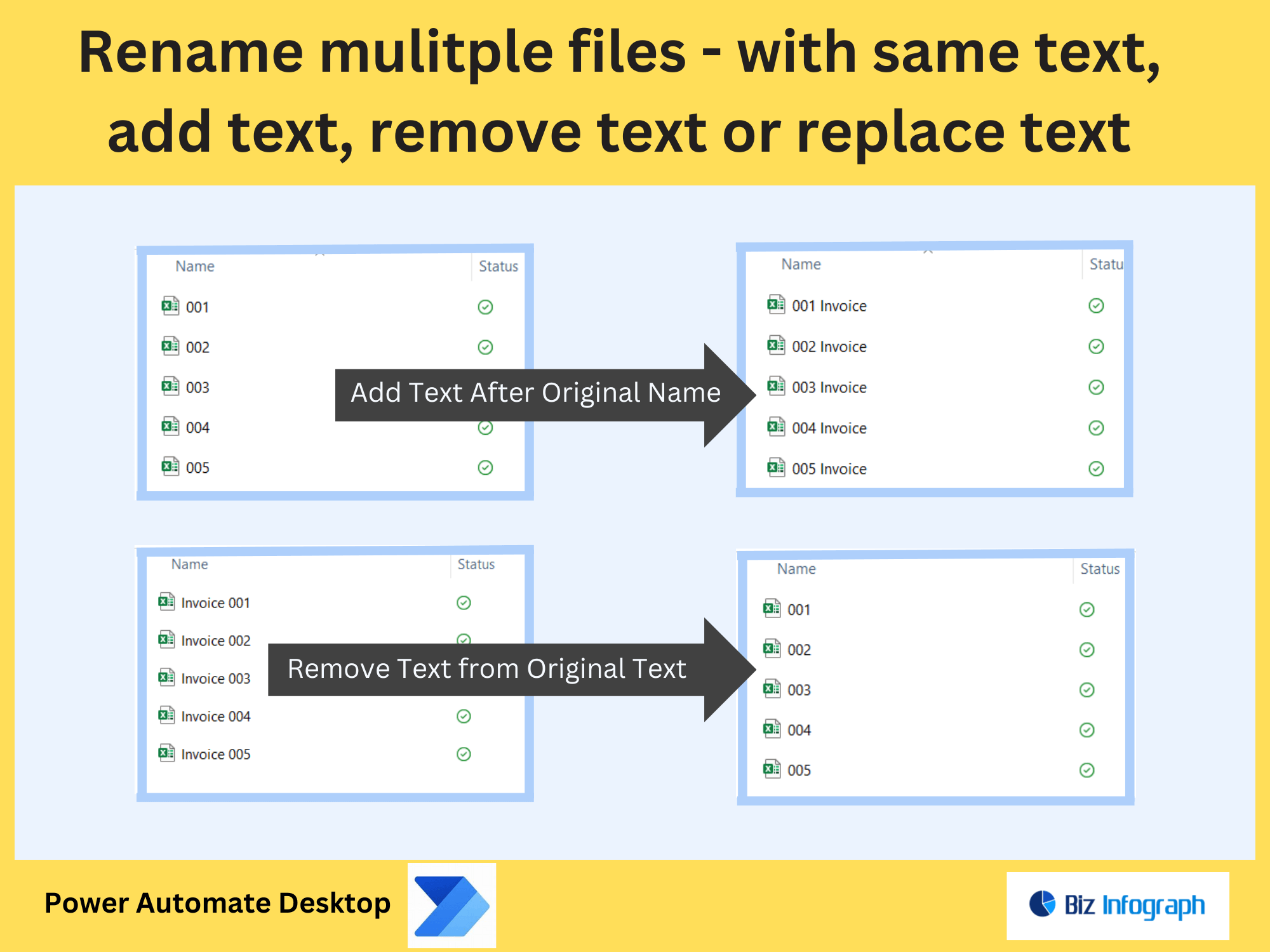
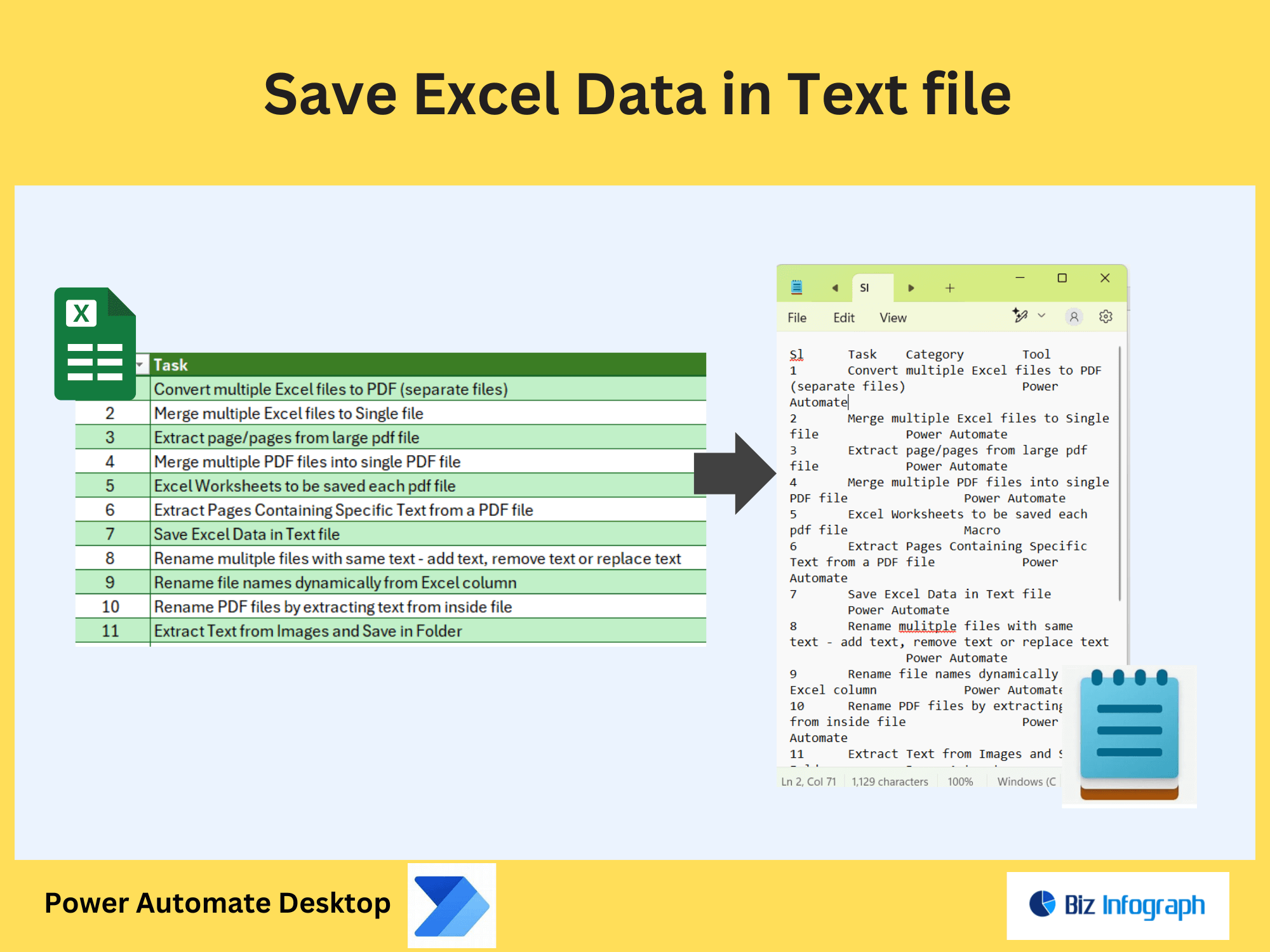
After extraction, use Power Automate to format text into structured outputs. Apply actions like “Compose” or “Replace” to clean data (e.g., remove extra spaces, add headers). Convert results into tables, CSV files, or append to a new PDF with formatted layouts. For instance, reformat extracted survey responses into a standardized report template.
H3: Exporting Results to a New PDF or External System
Export extracted text to a new PDF or external platforms like SharePoint, Excel, or CRM systems. Use Power Automate to generate summaries, append metadata, or merge extracted data with templates. For example, create audit reports by combining extracted compliance data into a polished PDF file for stakeholders.
Advanced Techniques for PDF Automation
Extracting Images and Pages from PDFs
Beyond text, Power Automate can extract images or specific pages from PDF files. Use connectors like Adobe PDF Services to split documents, save pages as separate files, or isolate images for cataloging. This is useful for archiving diagrams from technical manuals or segregating contract annexures.
Automating Bulk PDF Text Extraction
Scale workflows to process bulk PDFs by looping through folders or file lists. Combine extract text, extract pages, and conditional logic to handle diverse documents. For example, batch-process invoices to extract vendor names and amounts, then populate a database.
Integrating PDF Extraction into Larger Workflows
Embed PDF text extraction into broader automation, such as approval workflows or data pipelines. For instance, auto-extract client details from contracts, route them for approval, and update CRM systems—all within a single Power Automate flow.
For ready-to-use Dashboard Templates:
- Financial Dashboards
- Sales Dashboards
- HR Dashboards
- Data Visualization Charts
- Power BI - Biz Infograph