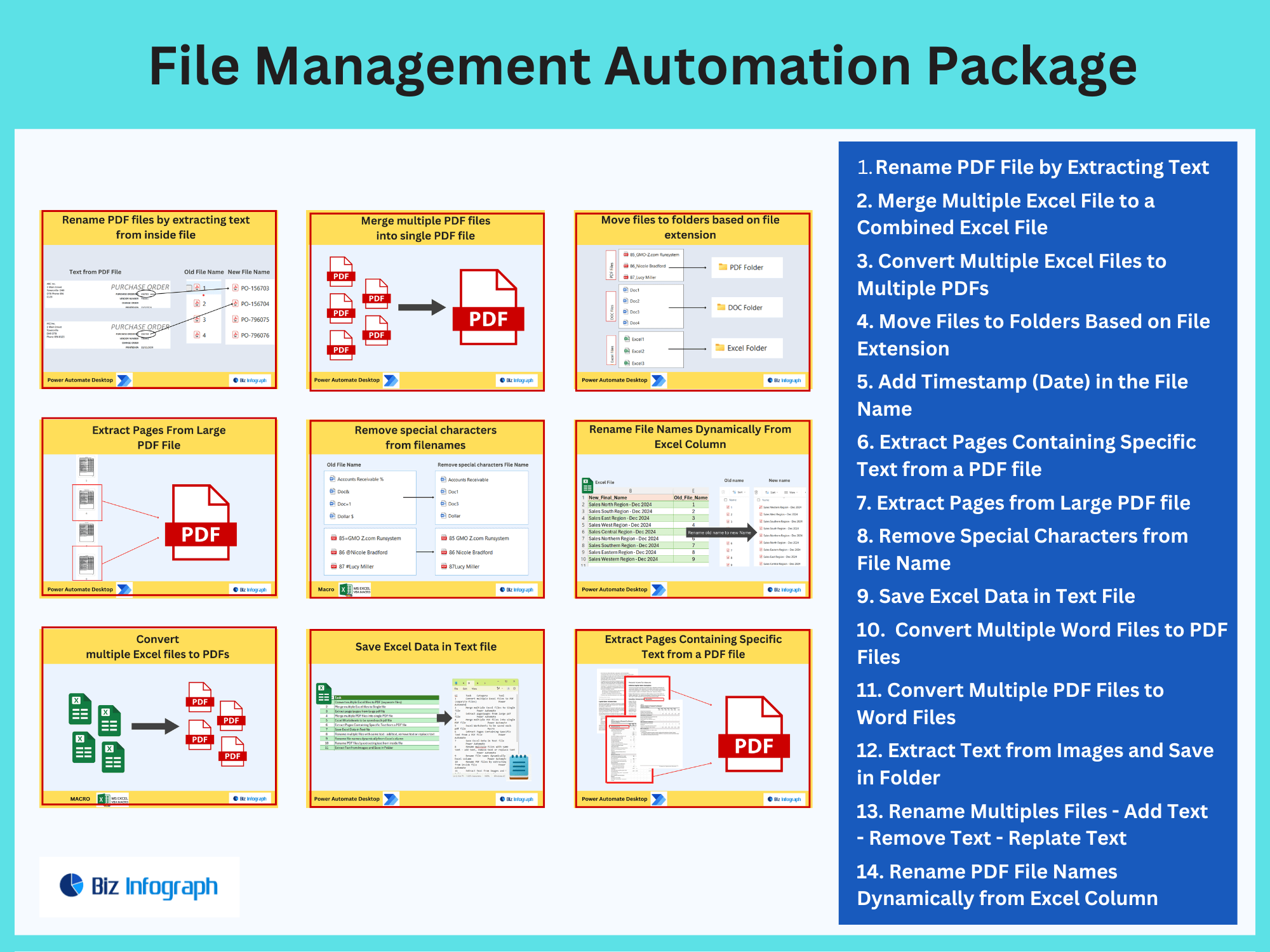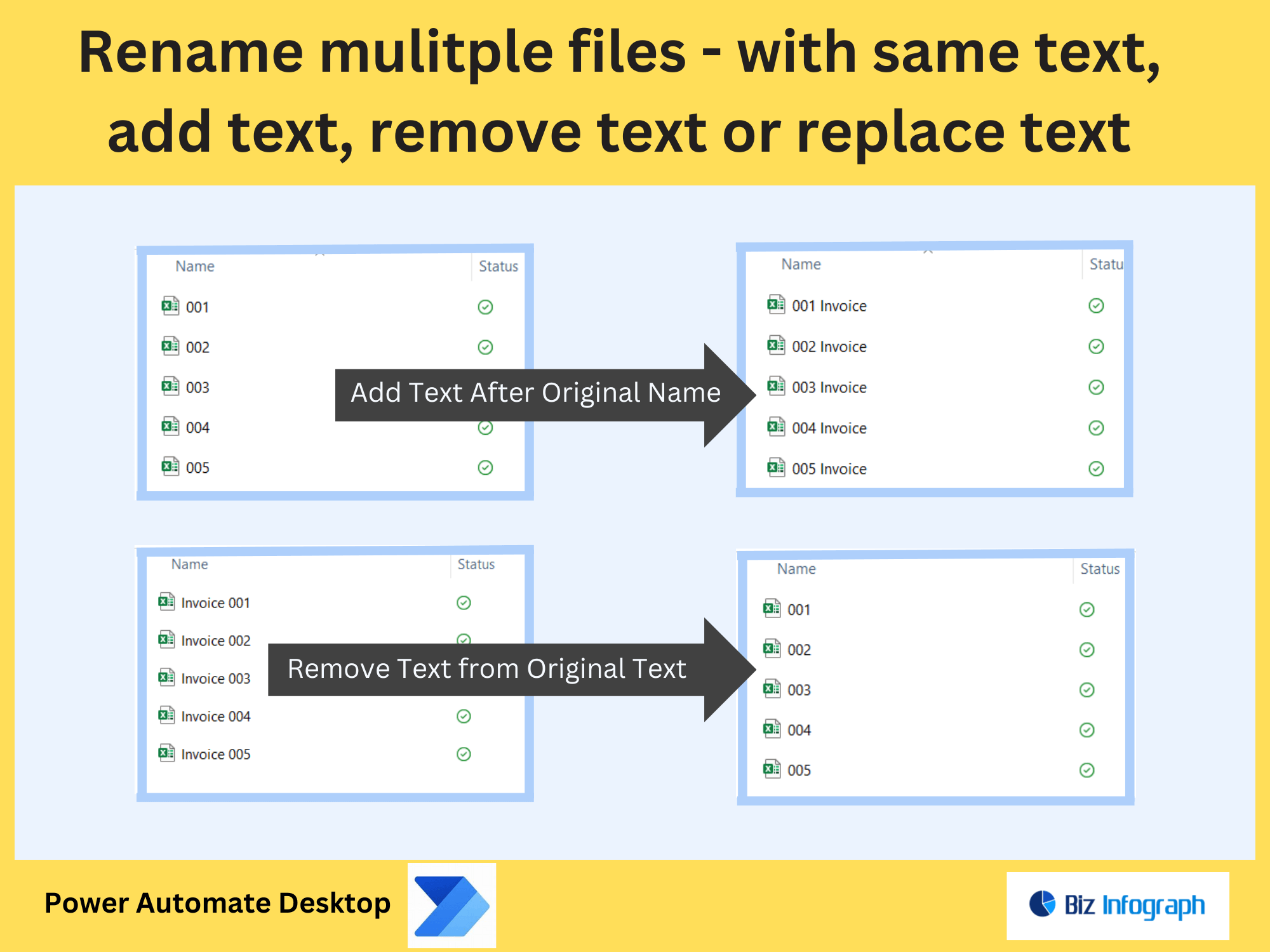
Extract Text from Images and Save in Folder by Power Automate
Why Use OCR to Extract Text from Images?
The Need for Digitizing Text from Images
Manually transcribing text from images is inefficient, especially for handwritten text, scanned documents, or photos containing critical data like invoices or receipts. OCR (Optical Character Recognition) in Power Automate Desktop automates this process, converting image-based content into editable text. For instance, extracting customer details from a scanned contract or digitizing handwritten notes for digital archives. Without automation, businesses face errors, delays, and inefficiencies. Microsoft Power Automate bridges this gap by enabling seamless text extraction from JPEGs, PNGs, or PDFs, ensuring data is searchable, reusable, and integrable into systems like SharePoint or databases. This is vital for industries like healthcare, finance, or logistics that handle multiple images daily.
Benefits of Automating Text Extraction with Power Automate
Automating text extraction from images using Power Automate offers speed, accuracy, and scalability. Leverage AI Builder’s prebuilt models or Tesseract OCR Engine to recognize text in over 100 languages, including handwritten text. For example, use the OCR action to process receipts, extract totals and dates, and save them to a text file or folder. This eliminates manual data entry, reduces errors, and accelerates workflows like invoice processing or compliance checks. Microsoft Learn resources and world on YouTube tutorials provide step-by-step guidance to learn how to easily extract text at scale. Additionally, editable text can be converted into PDFs or integrated into CRM systems, enhancing data accessibility.
How to Extract Text from Images Using Power Automate
Setting Up Power Automate for OCR Text Extraction
-
Trigger: Start with a trigger like “When a file is added” to a folder in SharePoint or OneDrive.
-
OCR Action: Add the OCR action in Power Automate Desktop and configure parameters like language (e.g., English) and output format (text/PDF).
-
Process Images: Use loops to handle multiple images, applying OCR to each file.
-
Integrate Tesseract: For complex layouts, integrate Tesseract OCR Engine via custom scripts to improve accuracy.
-
Save Output: Define a folder path (e.g.,
Output/Extracted_Text_%timestamp%.txt) to store results.
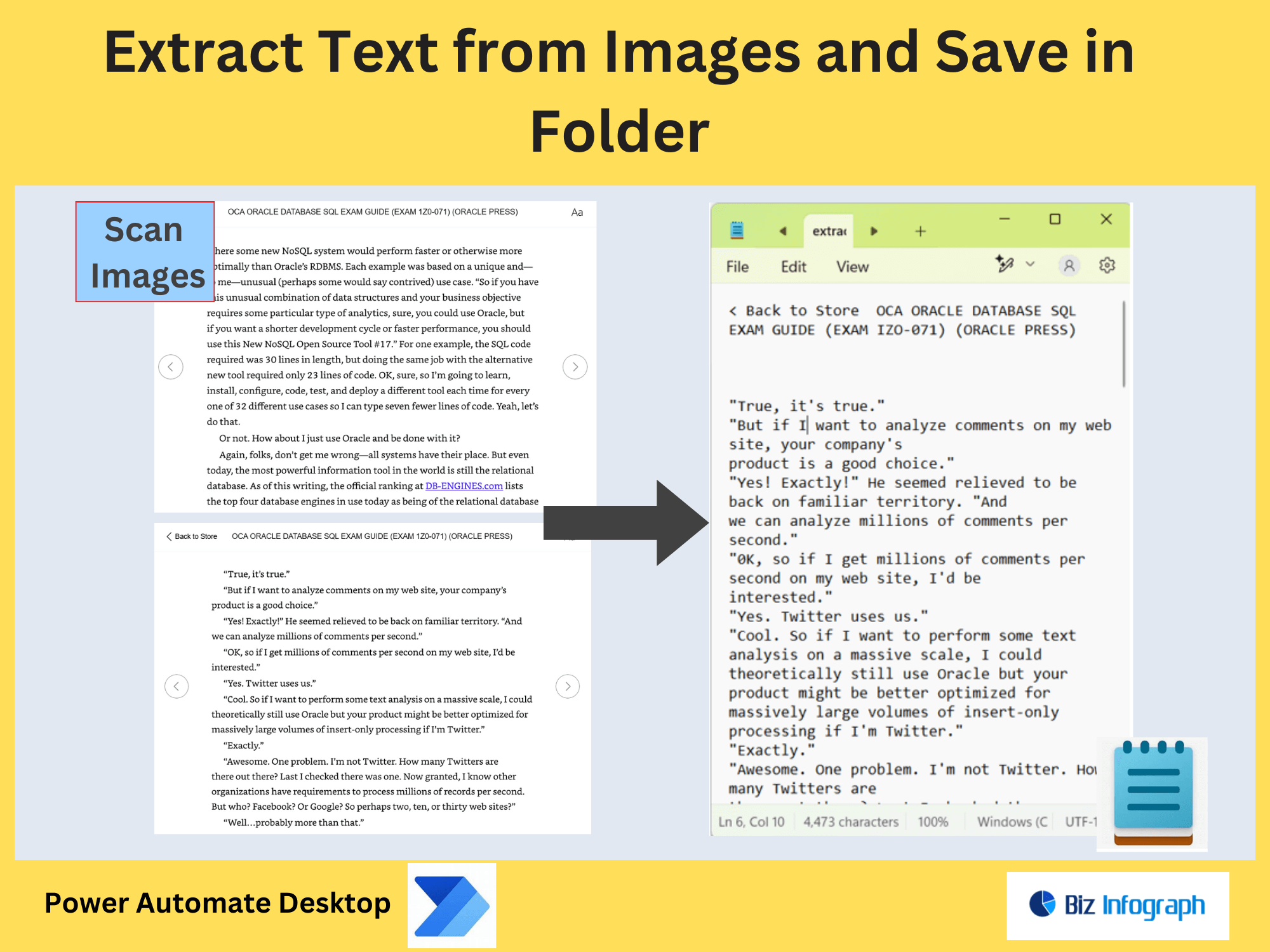
Using the OCR Action to Extract Text from Images
The OCR action in Power Automate converts text from images into machine-readable format. For example:
-
Upload a scanned invoice image.
-
Use the OCR action to extract text, including amounts and vendor names.
-
Copy text to clipboard or save it as a text file in a designated folder.
For handwritten text, enable AI Builder’s text recognition model to improve accuracy. Adjust parameters like confidence thresholds to filter low-quality results.
Step-by-Step Guide to Save Extracted Text in Folders
Extracting Text from Images with Optical Character Recognition
-
Upload Original Content: Access images via email attachments, SharePoint, or local storage.
-
Apply OCR: Use Power Automate Desktop’s OCR action to process the image. The prebuilt model detects text, tables, and even handwritten text.
-
Clean Data: Remove unwanted characters using regex or split text into sections.
-
Export: Save editable text to a folder or convert it into a PDF for structured storage.
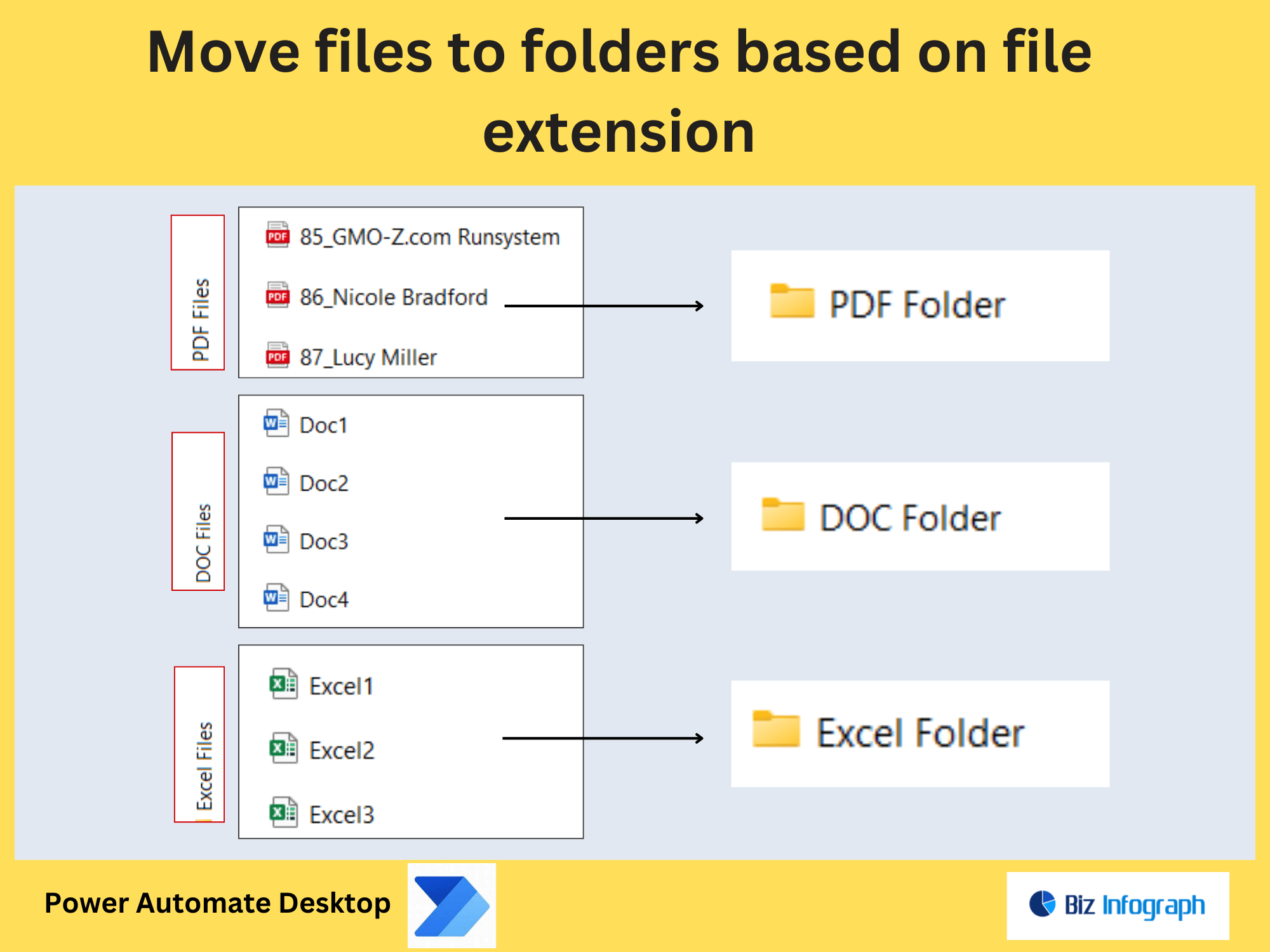
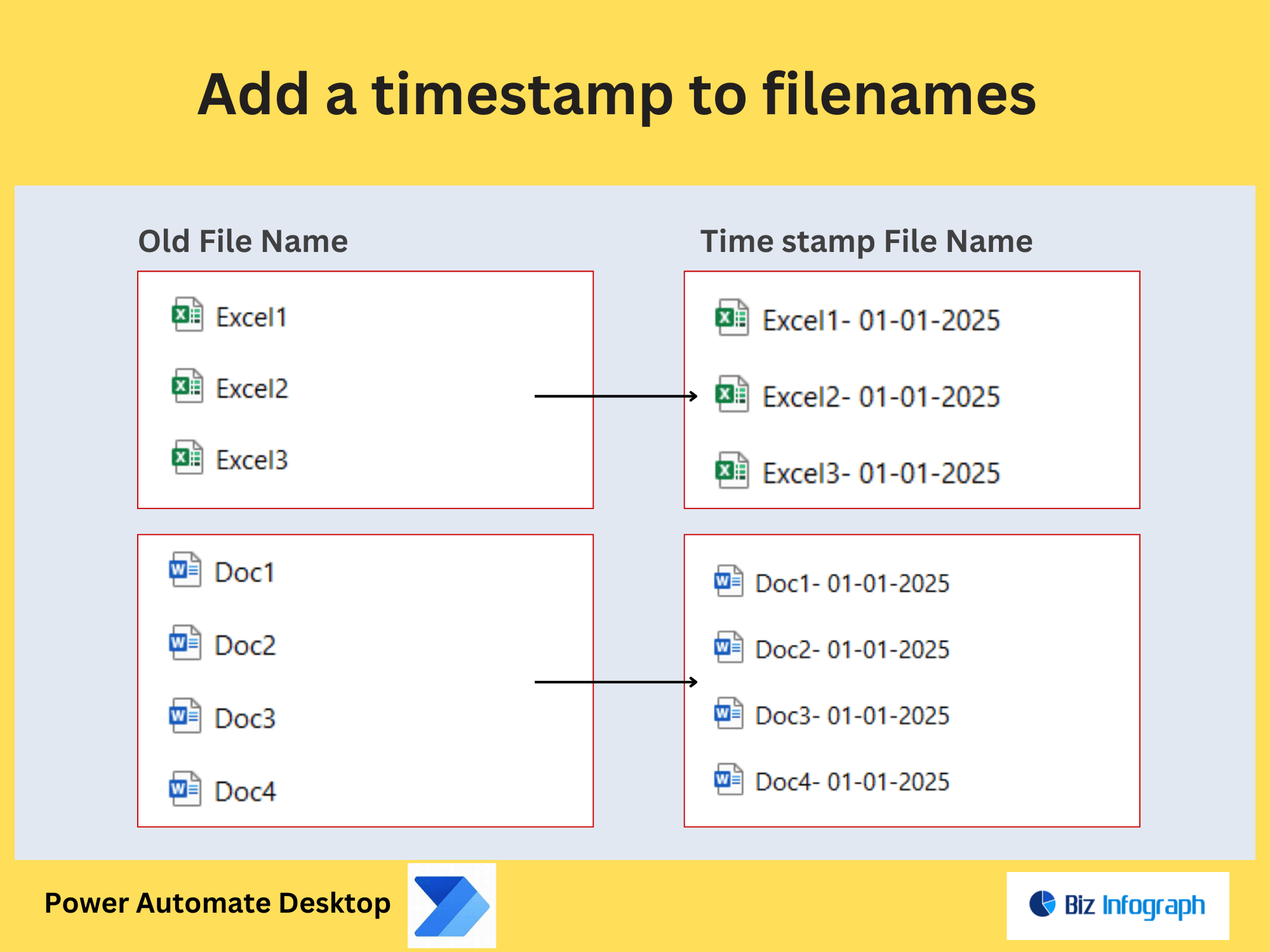
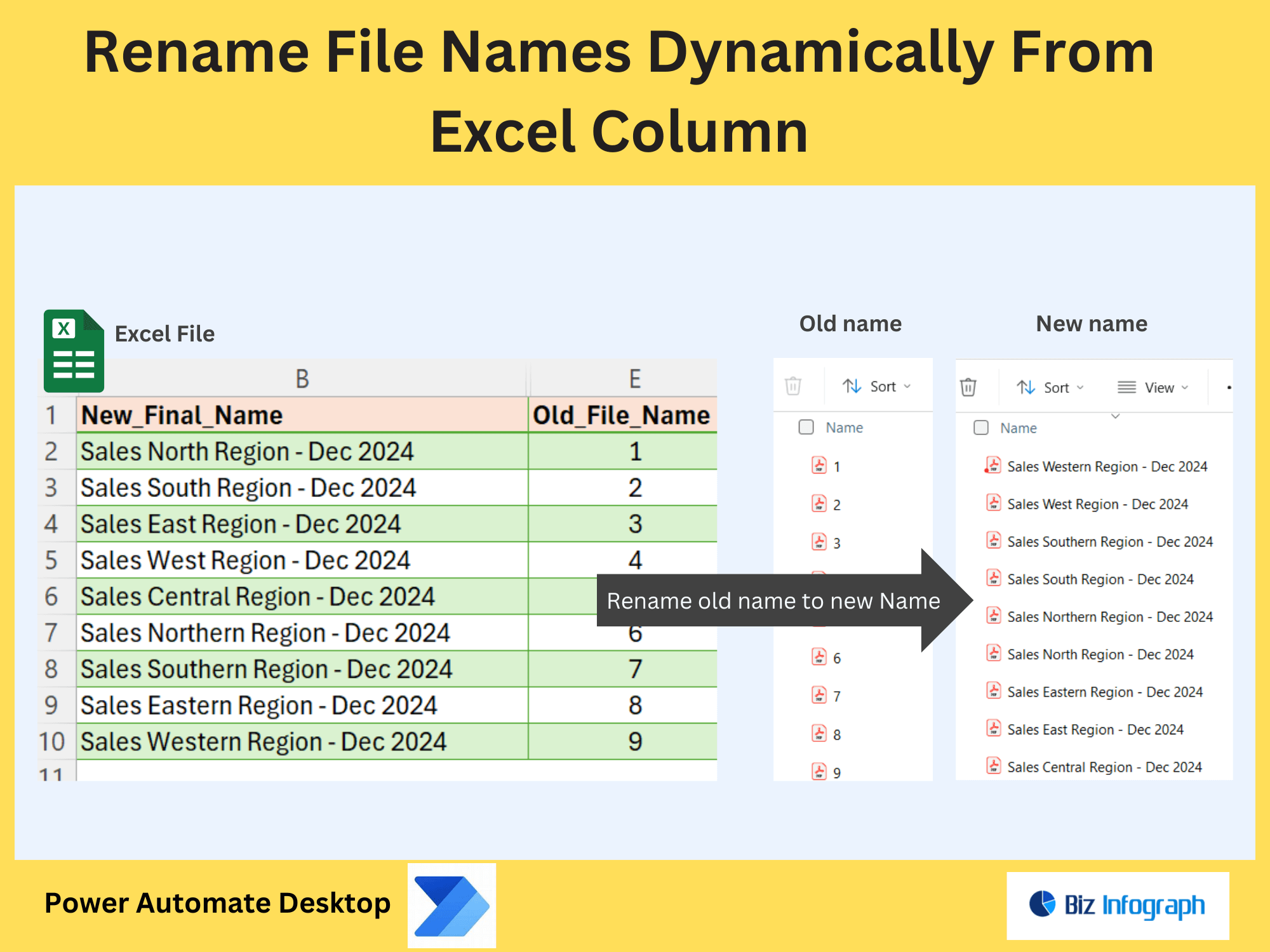
Configuring Folder Paths and File Naming Conventions
Organize extracted text by defining dynamic folder paths (e.g., Finance/Invoices_%year%). Use parameters to standardize file names, such as including the source image’s name or date. For example:
-
Text File:
Invoice_2024-10-15.txt -
PDF:
Report_%timestamp%.pdf
This ensures easy retrieval and compliance with naming policies.
Advanced Techniques and Additional Resources
Integrating Tesseract OCR Engine for Enhanced Accuracy
For specialized text extraction (e.g., multilingual or low-quality scans), integrate Tesseract OCR Engine with Power Automate Desktop. Configure custom parameters like language packs or page segmentation modes. Example:
-
Use Tesseract to process a handwritten note in French.
-
Save the extracted text to a folder with a “_FR” suffix.
This integration is ideal for academic or legal sectors needing high precision.
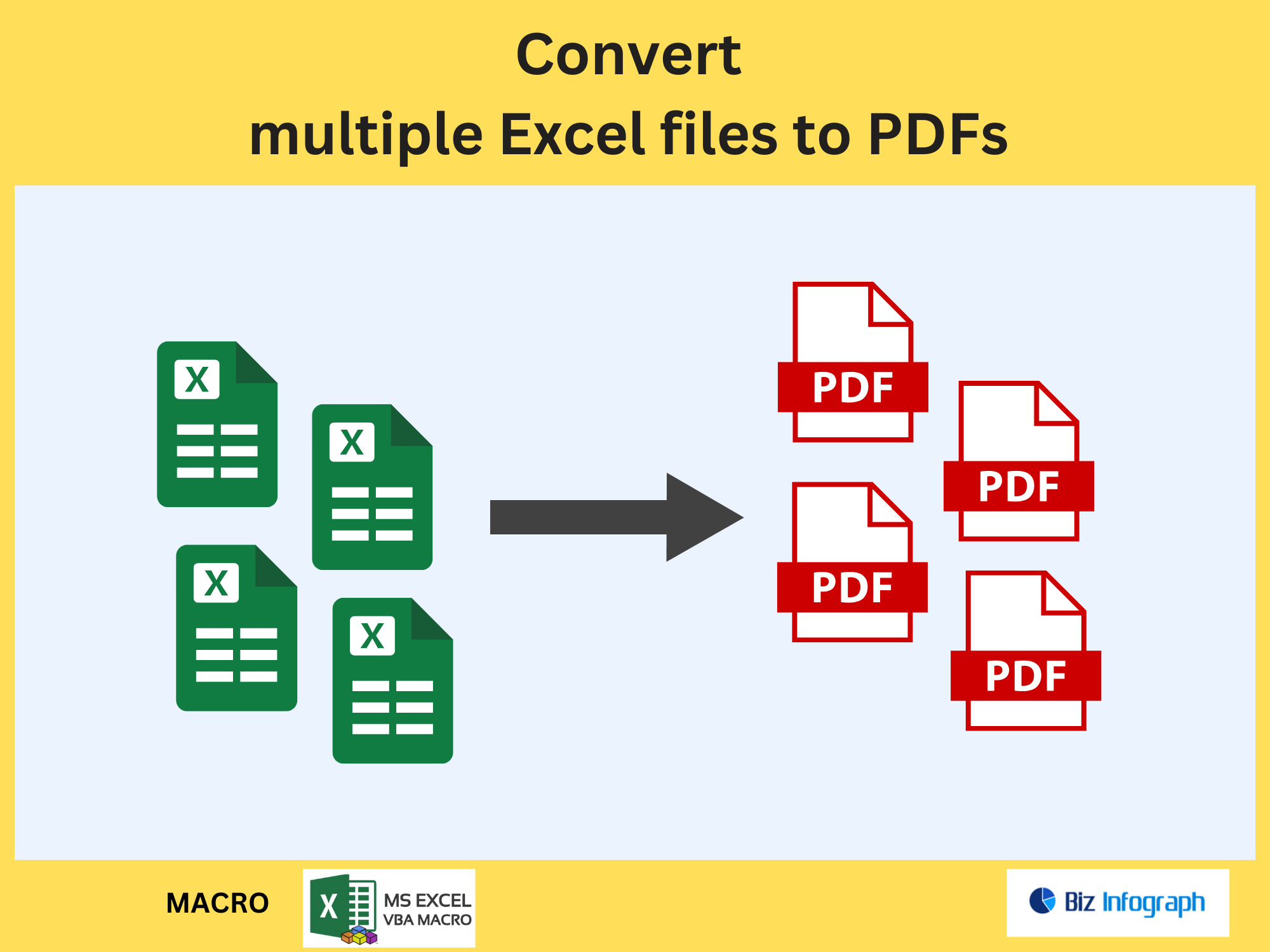
Batch Processing Multiple Images and Exporting to PDF
Use Apply to Each loops in Power Automate to process multiple images in bulk:
-
Extract Text: Run OCR on each image.
-
Compile Results: Merge extracted text into a single PDF using Adobe Acrobat actions.
-
Export: Save the PDF to SharePoint or email it to stakeholders.
This workflow is perfect for digitizing archives or creating searchable PDF reports from scanned documents transcript.
For ready-to-use Dashboard Templates:
- Financial Dashboards
- Sales Dashboards
- HR Dashboards
- Data Visualization Charts
- Power BI – Biz Infograph